
Google Gemma 3 QATモデル:高度なAIを一般のハードウェアへ
Googleは、高性能なGemma 3 27B QATモデルの量子化バージョンを公開しました。これにより、最先端のAIを一般消費者向けのハードウェアで実行できるようになります。この新しい量子化対応トレーニング(QAT)モデルは、メモリ要件を大幅に削減しながら、元の性能を維持します。これは、高度なAI機能を個人のデバイスにもたらす上で、大きな転換点となります。

スーパーコンピューター級の性能を一般のGPUへ
ニューヨークのブルックリンにある小さなアパートで、ソフトウェア開発者のマヤ・チェンは、通常は高価なクラウドサービスや専用ハードウェアを必要とする複雑なAI画像生成とテキスト分析を実行しています。彼女の秘密は何でしょう?それは、Googleが新たに公開したGemma 3 27B QATモデルを搭載した、2年前のNVIDIA RTX 3090グラフィックスカードです。
「これは画期的です」とチェンはシステムをデモンストレーションしながら説明します。「スーパーコンピューターレベルのAIを、すでに持っているハードウェアで実行できているのですから。このリリース以前は、それは不可能でした。」
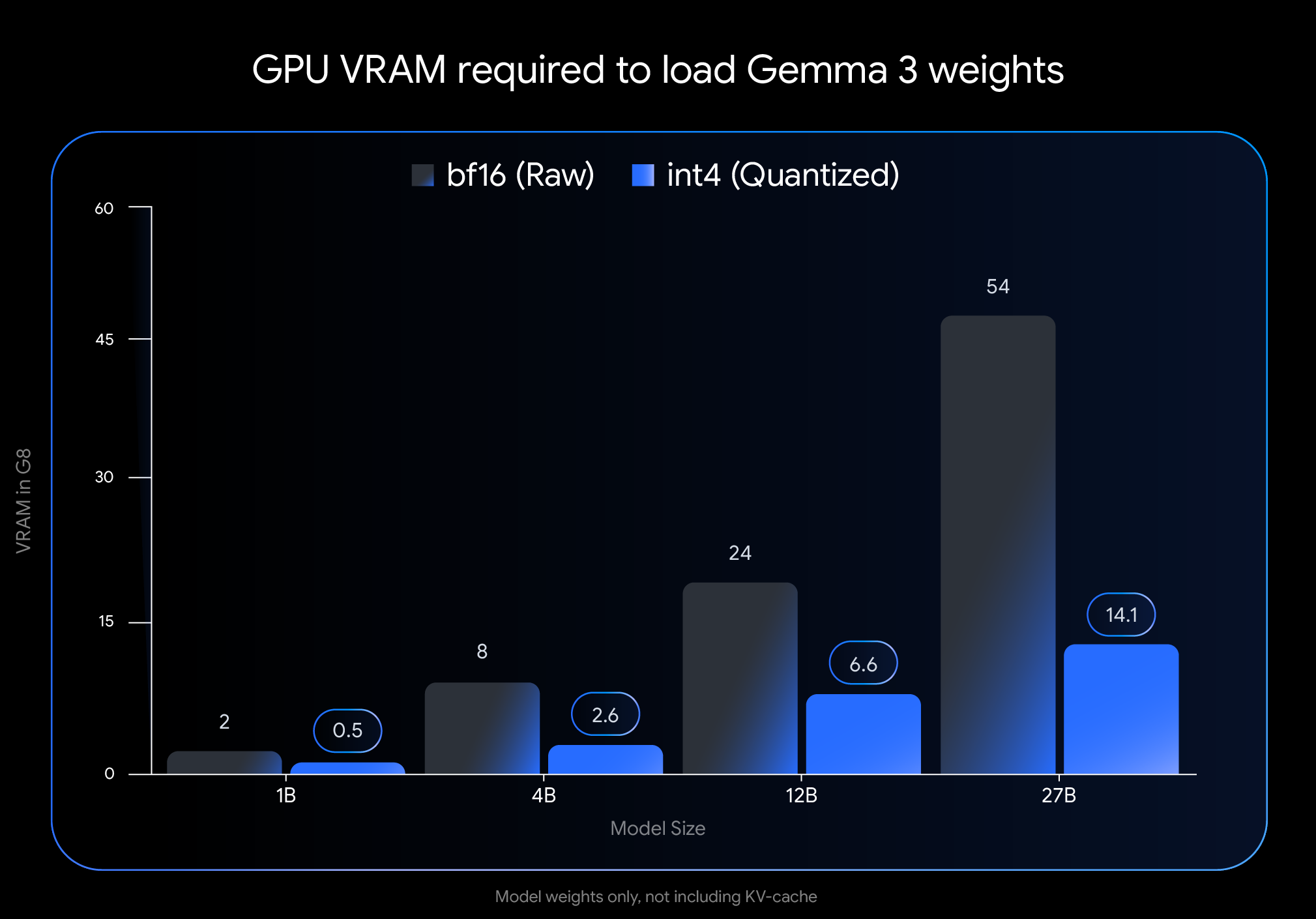
チェンの経験は、Googleが4月18日に発表したことの可能性を示しています。それは、広く利用可能な一般消費者向けハードウェアで効率的に実行できるようにすることで、最先端のAIへのアクセスを民主化することです。先月のGemma 3の発表は、主要なオープンモデルとしての地位を確立しましたが、高いメモリ要件により、高価な専用ハードウェアへの展開に限定されていました。新しいQATモデルは、この状況を完全に変えます。
モデル圧縮における技術的なブレークスルー
量子化モデルは、AIモデル圧縮における技術的なブレークスルーを表しています。従来のモデルサイズを削減する方法では、多くの場合、パフォーマンスが大幅に低下しましたが、Googleの量子化対応トレーニングの実装は、新しいアプローチを導入します。
従来のトレーニング後の量子化方法とは異なり、QATは圧縮プロセスをトレーニングフェーズ自体に組み込みます。トレーニング中に低精度演算をシミュレートすることにより、モデルは、最終的に数値精度が低下した状態で展開された場合でも、最適に機能するように適応します。
「このアプローチを特に効果的にしているのは、トレーニング方法です」と、モデルを分析した機械学習研究者は述べています。「約5,000ステップでQATを適用し、非量子化チェックポイントからの確率をターゲットとして使用することで、標準的な量子化手法と比較して、perplexityの低下を54%削減しました。」
メモリ要件への影響は劇的です。Gemma 3 27BモデルのVRAMフットプリントは、54GBからわずか14.1GBに縮小します。これは、約74%の削減です。同様に、12Bモデルは24GBから6.6GBに、4Bモデルは8GBから2.6GBに、1Bモデルは2GBからわずか0.5GBに減少します。
これらの削減により、以前はアクセスできなかったモデルを、一般消費者向けハードウェアで利用できるようになります。フラッグシップの27Bモデルは、NVIDIA RTX 3090などのデスクトップGPUで快適に動作するようになり、12Bモデルは、NVIDIA RTX 4060などのラップトップGPUで効率的に動作できます。
実際のパフォーマンスがアプローチを検証
Googleの実装を以前のモデル量子化の試みと区別するものは、パフォーマンスへの影響が最小限であることです。独立したベンチマークによると、QATモデルは、元の精度と比較して、精度を1%以内に維持しています。
人間の好みに基づいたAIモデルのパフォーマンスを広く評価するChatbot Arena Eloランキングでは、Gemma 3モデルは非常に高いスコアを獲得しています。27Bモデルは1338のEloスコアを達成し、競合他社よりもはるかに少ない計算能力しか必要としないにもかかわらず、上位のオープンモデルの仲間入りを果たしています。
コミュニティからのフィードバックも、これらの公式な指標を裏付けています。開発者フォーラムのユーザーは、QATモデルが他の量子化モデルよりも「賢く感じる」と報告しています。困難なGPQA diamond metricを使用した直接比較では、Gemma 3 27B QATは、より少ないメモリを使用しながら、他の量子化モデルよりも優れたパフォーマンスを発揮しました。
「リアルタイムアプリケーションでは、ほぼ瞬時の応答時間が見られました」と、モデルをモバイルアプリケーションに統合した開発者は述べています。「これにより、レイテンシとリソースの制約が重要な要素となるエッジ展開に、Gemma 3が実用的になります。」
マルチモーダル機能がユースケースを拡大
Gemma 3は、生のパフォーマンスを超えて、テキスト処理以外の機能拡張を可能にするアーキテクチャの革新を取り入れています。ビジョンエンコーダーの統合により、モデルはテキストと並行して画像を処理できますが、一部の専門家は、大規模な専用システムと比較して、視覚的な理解の深さに限界があることを指摘しています。
もう1つの重要な進歩は、拡張されたコンテキストウィンドウのサポートです。ほとんどのモデルで最大128,000トークン、1Bモデルで32,000トークンです。これにより、AIは、ほとんどの一般消費者がアクセスできるモデルよりもはるかに長いドキュメントや会話を処理できます。
「インターリーブされたローカル/グローバルアテンションメカニズムの実装により、長文コンテキスト推論に必要なメモリフットプリントが大幅に削減されます」と、アーキテクチャに精通した機械学習エンジニアは説明します。「これにより、理解度を犠牲にすることなく、一般消費者向けGPUで広範なドキュメントを処理することが可能になります。」
エコシステムのサポートが導入を促進
Googleは統合の容易さを優先し、一般的な開発者ツールと互換性のある形式でモデルをリリースしました。公式のint4およびQ4_0非量子化QATモデルは、Hugging FaceおよびKaggleで入手でき、Ollama、LM Studio、Apple Silicon用MLX、Gemma.cpp、およびllama.cppなどのツールからのネイティブサポートが提供されています。
このエコシステムのサポートにより、独立した開発者や研究者の間での採用が加速されています。ディスカッションフォーラムには、多様なハードウェア構成とユースケースでの展開の成功例が多数寄せられています。
「幅広いツールサポートと簡単なセットアッププロセスが非常に重要でした」と、モデルを教育アプリケーションに統合した開発者は述べています。「数時間以内にローカルに展開できたため、クラウドコストを削減しながら、応答品質を維持できました。」
制限事項と今後の方向性
進歩にもかかわらず、専門家は、Gemma 3モデルが依然としていくつかの制限に直面している分野を特定しています。長いコンテキストを処理できますが、一部のユーザーは、特に複雑な分析タスクの場合、非常に広範な入力全体で深く推論する能力は依然として課題であると指摘しています。
ビジョンコンポーネントは効率的ですが、一部の大規模な共同トレーニングされたマルチモーダルモデルほど高度ではありません。これは、微妙な視覚的理解を必要とするタスクのパフォーマンスに影響を与える可能性があります。
さらに、一部の機械学習研究者は、Gemma 3のパフォーマンスの多くは、おそらくGoogle独自のGeminiファミリーからの、より強力なティーチャーモデルからの洗練された知識蒸留によるものであると指摘しています。この依存関係は、トレーニング後の方法論における不透明さと相まって、より広範なAI研究コミュニティによる完全な再現性を制限します。
AI開発の民主化
今回のリリースは、高度なAI機能をより幅広い開発者、研究者、愛好家が利用できるようにするための重要な一歩となります。一般的なハードウェアでのローカル展開を可能にすることで、Gemma 3 QATモデルは、コストと技術的な要件の両面で参入障壁を低減します。
「これは単なる技術的な能力以上のものです」と、ブルックリンの開発者であるチェンは語ります。「誰がこれらの技術で革新を起こせるかということです。強力なAIが一般消費者向けハードウェアでローカルに実行されると、専門的なインフラストラクチャに余裕のない個人や小規模チームに扉が開かれます。」
AIがテクノロジー開発のさまざまな側面にますます影響を与えるようになるにつれて、洗練されたモデルをローカルで実行できることは、主要なテクノロジー企業を超えたイノベーションに変革をもたらす可能性があります。GoogleのGemma 3 QATへのアプローチは、最先端のAIが集中管理されたリソースではなく、民主化されたツールになる未来を示唆しています。
このビジョンが完全に実現するかどうかは、テクノロジーがどのように進化し、より広範な開発者コミュニティがこれらの機能をどのように受け入れるかによって異なります。しかし、今のところ、最先端のAI研究と実用的な展開とのギャップは大幅に縮まっており、AIアクセシビリティの未来に大きな影響を与える可能性のある開発となっています。