
バイトダンスが「Seed 1.5-VL」を発表:Gemini Pro 2.5に匹敵する、革新的な画像・言語AIモデル
マルチモーダル人工知能において大きな飛躍となる、バイトダンスのSeedチームが最新の画像・言語大規模モデルである**「Seed 1.5-VL」をリリースしました。これは世界のAI競争における重要な節目となります。「Seed 1.5-VL」はわずか200億のアクティブなパラメーター**で設計されていますが、**Googleの「Gemini 2.5 Pro」に匹敵する性能を発揮し、幅広い実際の視覚タスクやインタラクティブタスクで最高水準(SOTA)**のベンチマークを打ち立てています。これらすべてを、大幅に抑えられた推論コストで実現しています。
🚀 何が起きたか?
2025年5月15日、バイトダンスは、SeedシリーズのマルチモーダルAIモデルにおける最新の進化形である「Seed 1.5-VL」を正式に発表しました。テキスト、画像、動画を含む3兆以上の高品質なマルチモーダルデータで事前学習されており、「Seed 1.5-VL」は、高度な視覚的推論、画像理解、GUI操作、動画分析を統合した、一つのシンプルなアーキテクチャです。
巨大なAIシステムとは異なり、「Seed 1.5-VL」は**Mixture of Experts(MoE)**アーキテクチャを採用しており、各タスクに対して総パラメーター数200億のうち一部のみをアクティブ化します。これにより、コンピューターの効率が劇的に向上し、デスクトップ、モバイル、組み込み環境全体で、リアルタイムでインタラクティブなAIアプリケーションに最適です。
比較的小さなモデルサイズにもかかわらず、「Seed 1.5-VL」は60件の公開評価ベンチマークのうち38件でSOTA(最高水準)の結果を出しました。これには以下が含まれます。
- 動画理解ベンチマーク19件中の14件
- GUIエージェントタスク7件中の3件
テストでは、複雑な推論、光学文字認識(OCR)、画像解釈、オープンボキャブラリー検出、防犯カメラ映像分析などで優れた能力を発揮しました。
現在、「Seed 1.5-VL」は**「Volcano Engine」のAPI**、そしてオープンソースコミュニティ向けにHugging FaceやGitHubを通じて公開されており、テストが可能です。
📌 重要なポイント
- マルチモーダル能力:画像、動画、テキスト、GUIタスクを人間レベルで理解し処理します。
- 効率性重視:アクティブなパラメーターは200億のみですが、Google Gemini 2.5 Proに匹敵する結果をより低コストで提供します。
- SOTAの実績:60件の公開ベンチマークのうち38件でトップ、特に動画およびGUIタスクで優れています。
- 実用的な用途:OCR、監視分析、有名人認識、比喩的な画像解釈で既にテストされています。
- オープンアクセス:「Volcano Engine」でAPIを提供、技術論文はarXivで公開、コードはGitHubにあります。
🔍 詳細分析
アーキテクチャと革新
「Seed 1.5-VL」は3つの主要なモジュールで構成されています。
- SeedViTビジュアルエンコーダー:画像や動画フレームから豊かな特徴を抽出する、5.32億パラメーターのエンコーダーです。
- MLPアダプター:ビジュアルエンコーダーと言語モデルを橋渡しし、画像/動画の特徴をマルチモーダルなトークンに変換します。
- 大規模言語モデル:推論効率を最適化した、200億パラメーターのMoEベースのLLMです。
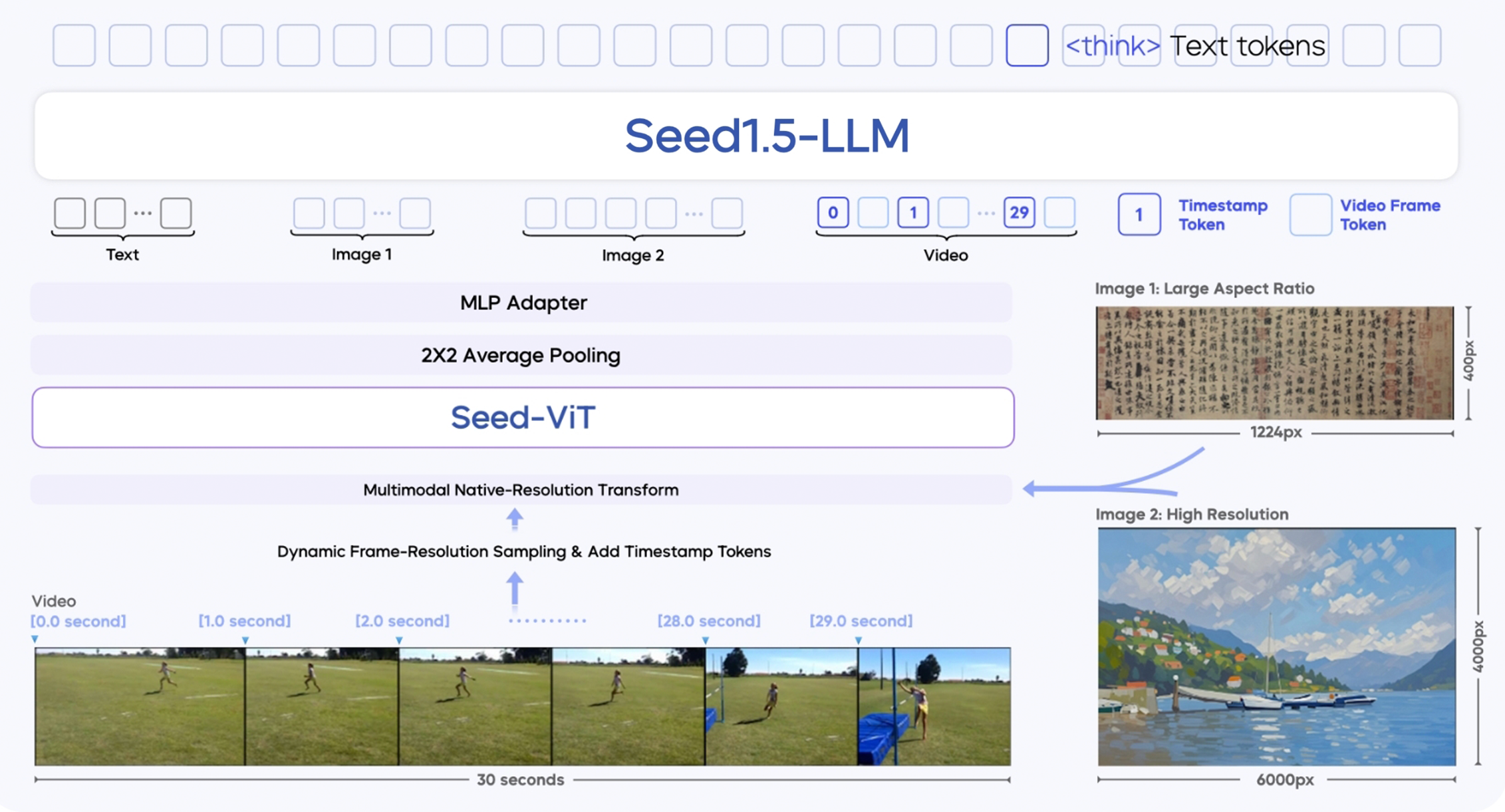
いくつかの技術革新を導入しています。
- マルチ解像度入力対応:画質と精度を維持します。
- 動画の動的なフレーム解像度サンプリング:動きの複雑さに基づいてフレームを選択することで、動画理解を向上させます。
- タイムスタンプトークンによる時間的強化:動画におけるオブジェクトの順序や因果関係の追跡を改善します。
- 3兆以上のマルチモーダルデータでの学習:幅広い領域への汎化能力を向上させます。
- 後処理による応答品質向上:リジェクションサンプリングやオンライン強化学習などを含みます。
強み
「Seed 1.5-VL」が優れている点:
- ビジュアル質問応答(VQA)とグラフ解釈
- GUI自動化タスク(ゲームやアプリ操作を含む)
- オープンエンドな視覚環境でのインタラクティブな推論
- 現実世界の用途(有名人識別、監視、比喩の理解)
多くの学術モデルに欠けている現実世界での堅牢さが評価されています。一部の評論家からは、OpenAIのo4やGoogleのGeminiと競合できる「非凡な実力者」とも評されています。

限界
強みがある一方で、「Seed 1.5-VL」にも完璧ではない点があります。
- 微細な視覚的課題:隠れた物体の数え上げ、色の類似性、不規則な配置などで課題を抱えています。
- 複雑な空間推論:迷路のナビゲーションやスライドパズルの解決といったタスクでは、不完全な結果となることがあります。
- 時間的な推論:フレーム間のアクションシーケンスの追跡に困難が生じることがあります。
これらはバイトダンスが認識しており、今後のバージョンで改善を目指していると思われる領域です。
競合状況
「Seed 1.5-VL」はAI開発競争の真っただ中で登場しました。
- Googleの「Gemini 2.5 Pro」(2025年5月6日発表)は、マルチモーダルリーダーボード(LMArena)で優位に立っています。
- OpenAIの「o3」と「o4-mini」(2025年4月17日発表)は、ツールの利用や強化学習を進めています。
- 中国国内の競合他社(テンセント、Doubaoなど)も画像認識や音声機能の強化を進めています。
投資アナリストは楽観的です。エージェントモデルとマルチモーダル機能は、次世代AIアプリケーション、特に企業向けソフトウェア、ERP、OA、コーディングアシスタント、オフィスツールにおいて重要な推進力になると見ています。
💡 ご存知でしたか?
- 「Seed 1.5-VL」は防犯カメラ映像から不審な行動を検知できます。これは、多くのモデルが効果的に対応できていない高度な現実世界の利用例です。
- 比喩的な画像を読み取り、その抽象的な関係性を説明できる数少ないモデルの一つです。
- リアルタイムでインタラクティブな、異なるモードを組み合わせたGUI操作が可能なモデルは、世界中でわずか3つ(Gemini Pro 2.5、OpenAI o4、Seed 1.5-VL)しかありません。
- バイトダンスは、はるかに少ないパラメーターでGemini Proの性能に匹敵しており、優れたモデル圧縮・最適化スキルを示しています。
- ネイティブ解像度を維持する変換を使用しており、従来のビジョンエンコーダーで起こりがちな画質劣化を防いでいます。
まとめ
「Seed 1.5-VL」は、バイトダンスがAI研究、特にマルチモーダル基盤モデルにおける世界的リーダーとしての地位を確立する上で、大きな節目となるものです。卓越した性能効率、堅牢な現実世界での能力、主要なベンチマークにおけるSOTAの達成により、GoogleやOpenAIといった企業に追いつくだけでなく、正面から競合しています。
産業界全体でAIの導入が進むにつれて、「Seed 1.5-VL」のようなモデルが最前線に立つでしょう。インテリジェントなエージェントを形成し、自動化を推進し、機械が知覚し、理解し、実行できることを再定義していきます。
CTOL編集者 Ken:バイトダンスの公式「Seed 1.5-VL」ページにある例を見ることを強くお勧めします。本当に印象的です。